
扬奇智能社区|mPLUG-2:模块化多模态基础大模型

本文系扬奇智能社区原创,如需转载、下载PPT请联系(微信号:834436689)以获得授权。
分享嘉宾|硕风,阿里达摩院
整理出品|扬奇智能社区
导读
mPLUG系列多模态预训练工作,探索一种模块化,轻量化,层次化的大一统多模态模型,可以灵活轻量化支持足够多的单模态/多模态任务。
当前的大一统的模型都很难在单模态,多模态任务上都取得很好的效果,我们认为在于不同模态,类型数据存在模态拉扯/纠缠(modality entanglement);很难让多/单模态可以相互协同提升(modality collaboration)。
我们提出模块化大一统模型mPLUG-2,不同的单/多模块基于对应数据进行层次化预训练,基于各种不同模态的大模型,结合instruction generation/instance discrimination,可以灵活拆拔不同的Module进行单/多模态任务(text,image,video)。




我今天主要给大家介绍的是模块化多模态大模型。我的分享主要分成三个部分。
第一部分是介绍下多模态技术的发展。多模态技术主要分成了两个阶段,从 17、18 年的时候刚开始做多模态预训练,到今年开始演化到了像 GPT-4 的这种多模态的模型。 第二部分介绍一下我们的工作,多模态大模型 m-PLUG,如果大家对多模态有所了解的话,应该对我们 m-PLUG 也有一定的认识。
第三部分介绍一下我们达摩院的中文开源社区,ModelScope,然后介绍一下我们 m-PLUG 的一些工作,做一些实战分析,最后介绍一下我们的这个 项目。


多模态训练大概分为两个阶段。在GPT-4 之前,大家主要是做这种类似于图文的训练,做的比较多的场景,有像 VQA 这种视觉问答,给出一张图片和问题,让机器回答。Image Caption 就是给一张图片,机器能够生成它的描述文本。Cross-modal Retrieval 其实是文搜图或者图搜文,Visual Grounding实际上就是要定位出这张图片里面的这种 binding box。这是之前多模态预训练最经典的 4 个任务。


从 17 年开始,多模态的发展分成了几个阶段。
刚开始的时候大家都是需要先做目标检测,然后抽取出来特征,第二阶段再做多模态预训练。
到了第二阶段,实际上进入了端到端的时代,从 2021 年开始。
从 22 年到 23 年之后,进入了这种大一统以及 scaling up 的阶段。
最近几月比较火的是这种类似于 GPT-4 的多模态大模型。
此外我们在做训练的时候,最重要的榜单是 VQA 榜单。大家可以看到,多模态刚提出的时候,大家的效果只有 65 点多,现在的结果已经到了 86 了,可以证明多模态发展非常的迅猛。 m-PLUG也是CVPR 2021 年 VQA Challenge 的第一名,我们也是在 2021 年的 9 月份左右以 81. 20 的成绩首次超越了人类。


多模态的技术发展,我这里就是列了几个比较有代表性的工作。
17-19 年左右,这种基于目标检测的方法的时候,大家主要做的方式是这种单双流的图文的特征融合,包括像 LXMERT、UNITER。
20-21 年的时候就进入这种端到端的时代,就比如像 Pixel-BERT等等,其实都是比较有代表性的工作。 到了 21 年之后,大家就开始做这种 scaling up 了,因为算力的发展,能够 scaling up 更多的数据以及模型的规模,其中比较有代表性的比如 ALBEF 以及我们的 m-PLUG。
然后到了去年,大家又开始探索这种大一统了,跟现在的 GPT-4 也有点一脉相承的感觉,就是用一个模型把所有的任务都生成的方。所以在去年的时候已经可以看到一定的端倪了。然后当时比较有代表性的工作,比如Coca、Flamingo以及等会会介绍的mPLUG-2。


从今年开始进入了大模型的时代,像GPT-4,没有开放 Demo 给大家体验,给了一些case,我们其实可以看到它几个 case 还是比较惊艳的,第一个就是这种视觉内容的细粒度的理解和推理,它能够 get 到不同插口的类型,以及能够理解非常细腻的笑法,都展示了这种非常强细粒度的理解和推理的能力。


它也展示了这种富文本图片的表格理解和推理,这也是最近比较热的研究方向,因为大家做自动化办公之后,以前的做法是一个非常复杂的pipeline,GPT-4 展现了多模态大模型是可以端到端的完成这类任务。比如它给了几个case,就是这种表格的理解,它能够非常详细地理解出每个表格的内容,给出比较好的 summarization 的消息。


以及给它一篇论文,它能够理解论文里面的一些细节,比如表格、 introduction 都能得到非常好的理解。左侧的数学公式的推理也能理解得非常好。
GPT-4出来后,掀起了今年多模态领域非常重要的一个发展关系,就是类GPT-4 ,因为GPT-4并没有开源,所以这块工作就非常多,大家都想用我们已知的一些方法逼近 GPT -4的效果。


所以大概分成了两类方法。
第一类就是基于系统的方法,把大语言模型当成一个中枢,它来决定调用什么样的视觉的expert。你比如像 Virtual ChatGPT,它需要调图片的理解 API, 检测图片生成,然后通过一个大语言模型作为中枢,可以做到类似于 GPT-4 的效果。一个模型可以做非常丰富、非常复杂的任务。像 HuggingGPT等等,都是和现在比较热的 agent true 一脉相承的想法。


另一类是这种端到端的,跟 GPT-4 类似,就是我们有一个多模态的语言模型,就可以做所有的比较复杂的任务,代表性的工作,像 MiniGPT-4,以及 LLAVA 、Kosmos-1,都是比较经典的工作,能用一个模型同时处理这种多模态和文本的能力。


下面介绍一下我们 mPLUG 的工作。 mPLUG 其实也是一直沿着多模态发展,我们也是 18、19 年开始做这个工作。从检测的,然后端到端的,到大一统的,再到大模型的,这种发展链路。我们包含了像图文的模型,像 mPLUG 的模块化模型, mPLUG-2,视频模型。我们也跟用户开源了一个现在最大的中文数据集,优酷-mPLUG。包含多模态的加速以及多模态的可解释。我们的发展其实也是跟业界的多模态预训练的发展是一致的


我们mPLUG 一直秉持的想法,就是模块化和轻量化,首先我们模型可能尽可能的 cover 过多的任务,并不需要用非常多的模型,像刚刚提到一些 expert 的方式来做这些任务。另一个思想就是轻量化,我们是想跟底座无关的,基于各个底座都可以把它应用到我们模块化的工作中。所以无论是不同模态的 input 或者output,以及它到底是做 understanding 或者 generation 的,我们都希望它这种层次化的预训练,可以轻量化的应用到各种的任务上。这就是我们 mPLUG 一直秉持的思想,轻量化和模块化。我们右侧的这个 table 列了现在比较多的一些大模型,像 Google 的Coca,像微软的 Flamingo 这些,他们都是这种大一统的模型。但是很难在所有的任务上都做到增大。比如像计算机视觉、LP、以及多模态、视频文本上都做到Sota,我们认为它的原因在于这么多的任务很难balance,并且起到模态协同的效果。我们借助这个思想,提出了 mPLUG-2 的工作。下面也列出了针对不同的单模态或者多模态的任务,我们可以插拔不同的模块,进行组合,然后做不同的多模态或者单模态的任务.


我们 mPLUG-2,主要两个motivation,第一个是这种高效的模块协同,多模态理论比较难的一个问题就是这么多的模态如何才能够高效地进行模态协同,所以提出了一个共享的 universal layer,它主要包括两部分,第一个是视觉和文本工信Self-Attention Layers 帮助不同的模态进行语义的对齐。然后又提出了一个 Specific Cross-attention 模块,将当前视觉表示映射到Original来保留模态Bias。另外一个是我们是既支持视觉的image,然后也支持 video ,所以我们希望能够协同这两个视觉模块,就提出了一个视觉编码器,这个视觉编码器通过一个共享的 transformer 来统一建模。因为对视频和图片来说,主要的区别在于视频有 control 的信息,但是对于每一帧的图片来说,跟图片本质上是一样的,所以我们通过共享的方式,统一建模这种空间的信息,针对video,额外增加了时序的模块来建模它的时序信息。


为了证明我们模型是比较通用、大一统的。我们就是在三个模态,包括像文本、图片、视频 的 15 个任务, 32 个数据集上,都取得了 SOTA 的效果。比刚刚提到的一些模型的效果更好。




我们也做了一个 “polation” study,对于单模态加入了 Virtual liar,大家一起 join the training ,对模型效果有非常显著的提升。我们右侧给出了可视化的图片,就是可以看到不同模态可以更好的对齐。
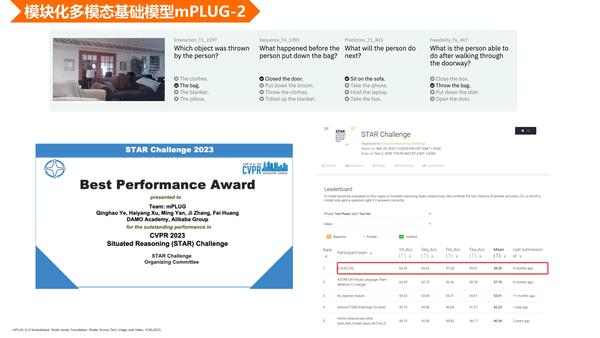
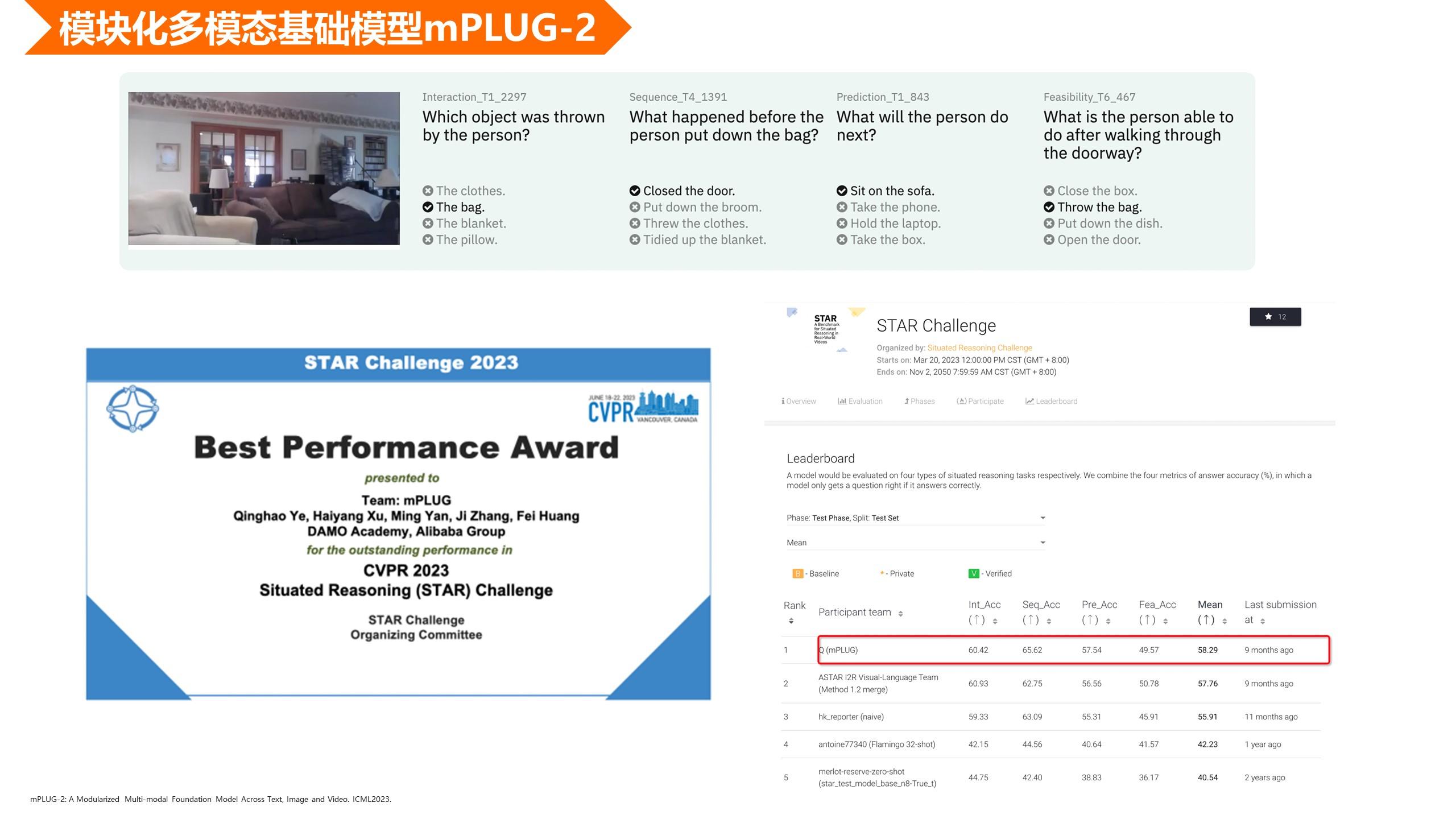
为了评测我们 mPLUG-2 的效果,我们也参加了今年那个 CVPR 的 vedio 推理的评测。大家可以看到上面的例子,就是给出一个视频之后,我们需要完成选择题,进行比较强的逻辑推理,我们也取得最好的效果,是今年的 best performance award。


我们也把我们这种模块化和轻量化的想法扩充到了多模态领域。如果大家最近关注多模态的话,我们这个猫头鹰的工作关注度还是非常高的。我们在做这个多模态大模型的时候,发现它有非常多的想象空间跟应用场景。比如我们下面给的一个case,像旅游的指南,我们给一张图片,让模型制定旅游指南,它能够非常详细的定制一些旅游攻略。以及像创意文案,给描述片,它能够生成创意文案,包括实用指南,给一个锤子怎么来使用等等。还有非常多的想象空间,所以最近多模态对话大模型才非常的火爆。


我们在刚刚多模态大模型的基础上,推广到了这种文章的大模型,刚刚提到了GPT-4,它比较亮眼的两个点,一是这种细粒度的理解的能力,另外一个就是对文档的理解能力,所以我们就是在刚刚提到的对话大模型的基础上,扩充到了文档的模型。然后我们把六种类型,包括图表、表格、自然图片、chat,图表,统一到这种 instruction 的范式,我们统一的模型,端到端的完成这些任务。右边是我们给的一些例子,我们都能比较好的这种理解图片中的含义。这些都是推动多模态对话大模型快速发展的原因,因为它相比之前的模型有非常大的想象空间,并且应用场景会更加的广泛。


我们也为了所有中国社区的发展,发布了中国最大的视频数据集,是和优酷联合发布的,优酷-达摩,我们人工标注了一些经典的Benchmark,像视频检索,视频的caption,以及视频的分类。我们总共开源了 1000 万视频文本图文对,我们从优酷 4亿 的原始视频中,把它抽取出来的。我们也基于用户的数据集,用了一个视频的大模型, mPLUG-vedio。左侧是我们的一个效果,我们可以针对视频进行各种问答以及细节的理解。我们主要是为了推动中文社区的发展,这点和扬奇智能的出发点是一致的。因为现在影响中国发展的其实主要就是数据集,相比英文来说,数据的质量以及版权和这种文化都有非常大的差距,所以我们才发布了这个最大的中文的视频数据集。
我们刚刚提到的这些工作,包括mPLUG-2,和优酷的工作以及文档、对话的东西,都在github上开源了。如果大家感兴趣,可以扫一下我们的二维码


ModelScope 是我们达摩院其实做的一个中文的社区,是为了推动中文社区的发展类,似于 Hugging face。所以我们刚才提到了很多工作,像mPLUG系列的很多模型,其实我们都在 ModelScope 上开源了,大家到 ModelScope 这个网页上只要搜 mPLUG 就可以搜到我们的模型了。

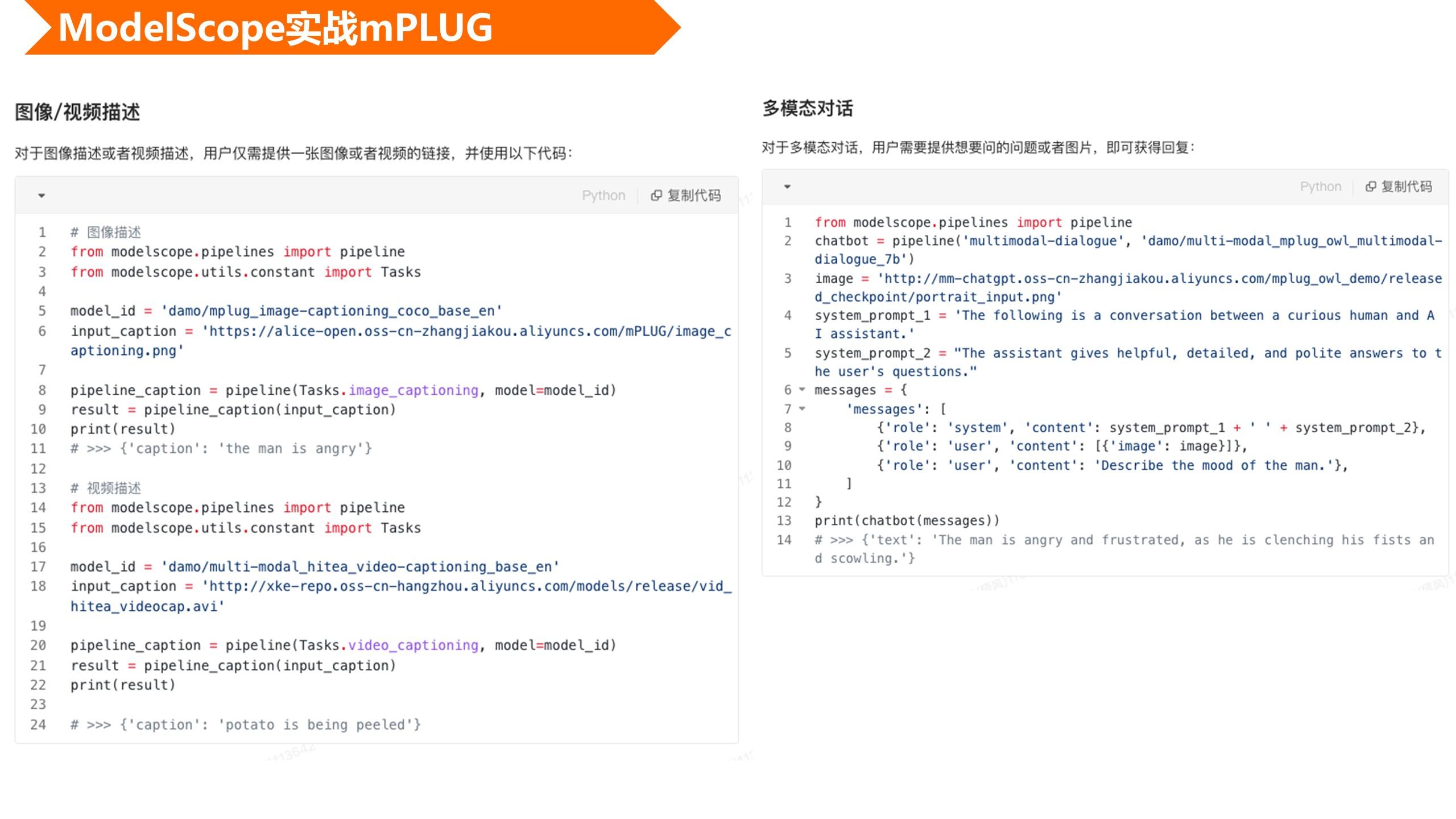
我们模型使用也非常简单,大家感兴趣也可以到ModelScope上试用。

我们 ModelScope 上还有一个创空间,主要是给中国社区提供一个 Demo 的空间。因为大模型时代其实看的就是大家的想象力,其实大家可以做出非常多的应用。我们刚刚提到的一些模型,都已经在创空间上部署了Demo。
这里是创空间的两个例子。比如给出王者荣耀的图片,它是能识别出信息的。大家如果比较感兴趣的话也可以直接去体验。

刚刚提到的优酷的数据集,我们也在ModelScope上开源了,大家感兴趣的话可以去体验下。
最后我们整个的mPLUG的项目也开源了,大家感兴趣的话欢迎关注我们的工作。
